recdnsfp
Recursive DNS Server Fingerprint

Problem
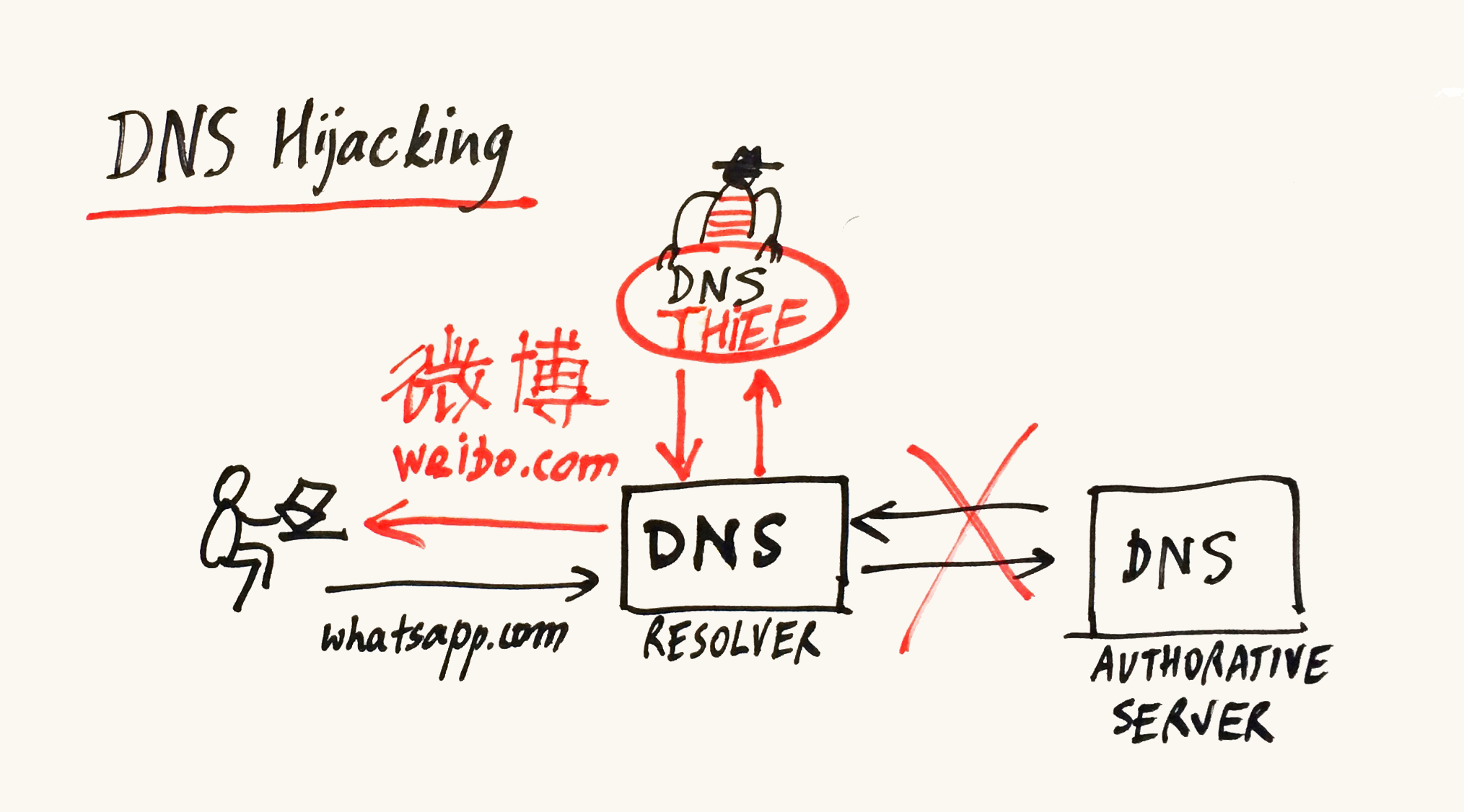
Google and a few other companies provide open dns resolvers to the people around the globe. Unfortunately it may happen that the resolver was hijacked and used for different purposes, such as redirecting to malicious pages or to block certain addresses (censorship).
Our goal is to identify hijacked resolvers by analyzing their fingerprints, in order to increase safety of Internet users. To do that, we utilize data collected via RIPE Atlas (atlas.ripe.net).
Solution
Our solution to the problem is based on observing characteristic features in replies to DNS queries. A hijacked server will likely run different software than the legitimate server, thus it should be possible to spot some small differences in server behavior. We build “fingerprints” of recursive DNS servers, or “feature vectors”. Next, we use machine learning algorithms to train computer to be able to discern between a legitimate server and a hijacked one.
For that purpose, we use the following features:
- Querying for “dnssec-failed.org”
- This domain has invalid DNSSEC records, thus a validating resolver should reply with an error. Instead, we’ve seen servers replying with NOERROR and redirects us to rogue IP addresses.
- We record the following features: request time (how long it took), reply size, header flags, rcode, counts of records in each section of DNS reply.
- Querying for a non-existent domain
- The server should reply with NXDOMAIN.
- We record: request time, reply size, rcode.
- Querying for DNSKEY with a 512-byte response size limit. (RFC 4034)
- The server should set the TC (truncated) flag in the response. Google servers don’t send any replies in such a case.
- We record: time, size, header flags, rcode.
- Querying for NSID (RFC 5001)
- If configured to do so, the server should give its DNS Name Server Identifier.
- We record: time, header flags, rcode.
- CHAOS TXT queries for bind.version and hostname.bind (RFC 4892)
- The server may reply with information on the software and/or host running the resolver.
- We record: times, sizes, rcodes, and binary flags if the query succeeded.
- Querying for “whoami.akamai.com”
- The query should return the IP address of the resolver, as seen by the authoritative DNS servers run by Akamai.
- We record: request time, AS number of the resolver IP.
- Checking if the resolver supports IPv6-only sites.
- It is possible to setup a domain that could be resolved only if the recursive resolver has IPv6 connectivity. An example is “ds.v6ns.test-ipv6.ams.vr.org”, used by the test-ipv6.com website.
We query the resolvers for the above features, and record the results in ARFF file format, used by popular data analysis environments, as Weka and RapidMiner.
Next, we train machine learning algorithms, C4.5 Decision Tree (in Weka) and Random Forests (in scikit-learn), building models for expected and not-expected server behavior.
Finally, using a separate testing dataset, we classify the fingerprints into two classes: valid (ok) and hijacked (non-ok). Thus, the computer is able to assess the probability of user connecting to a valid server by issuing a few DNS queries and running a machine learning algorithm.
Implementation
We used all RIPE Atlas probes (~9000 probes) to send DNS queries to 8.8.8.8. Each probe issued several queries, a single query covered one of the features described above (e.g. DNSSEC validation, IPv6 only-domain reachability, NXDOMAIN redirection, …). Next, we parse the results (many JSON files) into single ARFF file using parsejson.py. Finally, we use the ml.py script to train a model, and to test the model on testing dataset.
Below are links to resources we based on:
- Measurements’ templates: https://github.com/recdnsfp/ripe_atlas_api_scipts
- Collected data: https://github.com/recdnsfp/datasets
- Tools: parsejson.py and ml.py: https://github.com/recdnsfp/parsejson
Results
TOP 20 countries (hijack %)
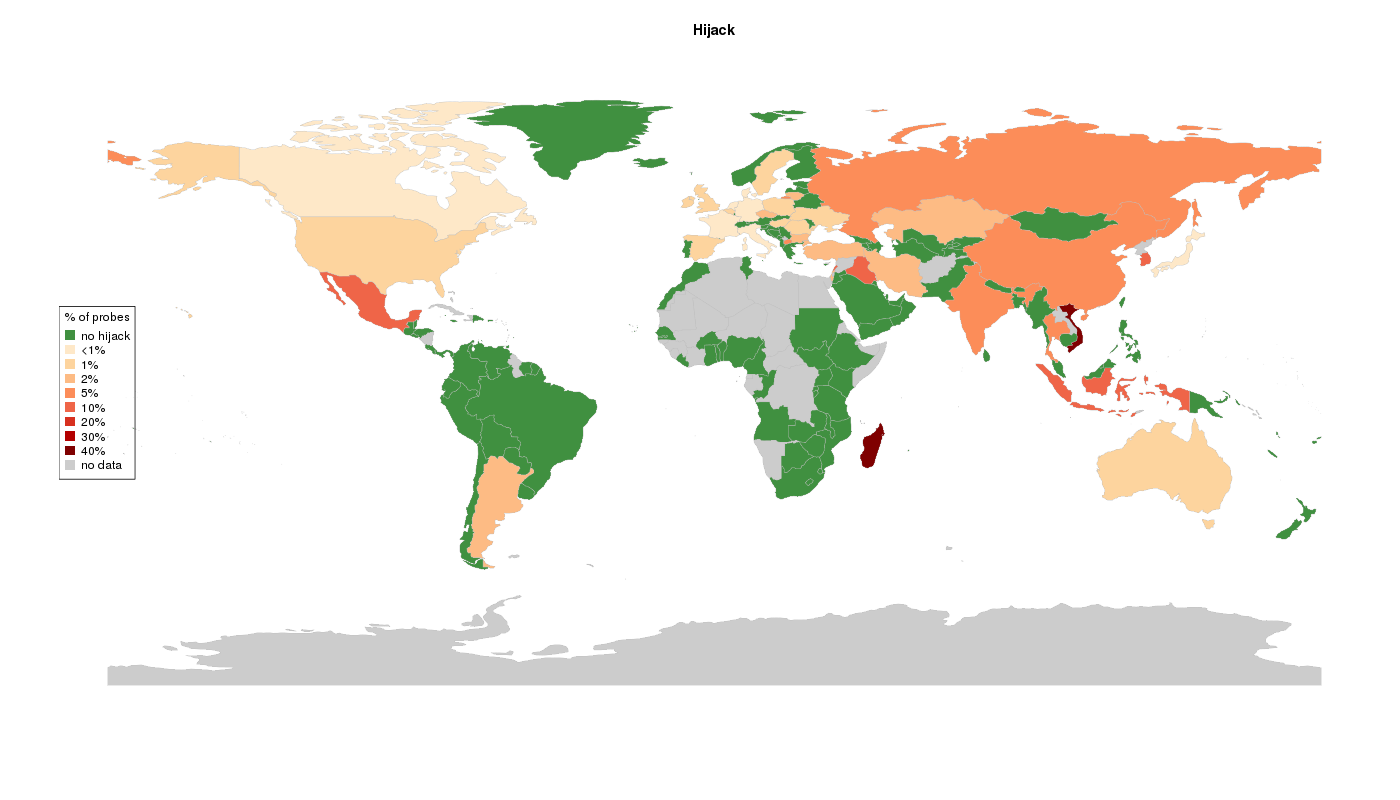
| no | cc | total_probes | hijacked | perc_hijacked |
|---|---|---|---|---|
| 1 | VN | 5 | 3 | 60.0 % |
| 2 | MG | 6 | 3 | 50.0 % |
| 3 | IQ | 5 | 1 | 20.0 % |
| 4 | ID | 40 | 7 | 17.5 % |
| 5 | KR | 14 | 2 | 14.3 % |
| 6 | LB | 9 | 1 | 11.1 % |
| 7 | MX | 9 | 1 | 11.1 % |
| 8 | CN | 10 | 1 | 10.0 % |
| 9 | RU | 445 | 34 | 7.6 % |
| 10 | MK | 14 | 1 | 7.1 % |
| 11 | IN | 31 | 2 | 6.5 % |
| 12 | TH | 17 | 1 | 5.9 % |
| 13 | LT | 20 | 1 | 5.0 % |
| 14 | HK | 24 | 1 | 4.2 % |
| 15 | IR | 48 | 2 | 4.2 % |
| 16 | AR | 26 | 1 | 3.8 % |
| 17 | KZ | 26 | 1 | 3.8 % |
| 18 | TR | 28 | 1 | 3.6 % |
| 19 | CZ | 241 | 7 | 2.9 % |
| 20 | BG | 71 | 2 | 2.8 % |
TOP 20 countries (hijack number)
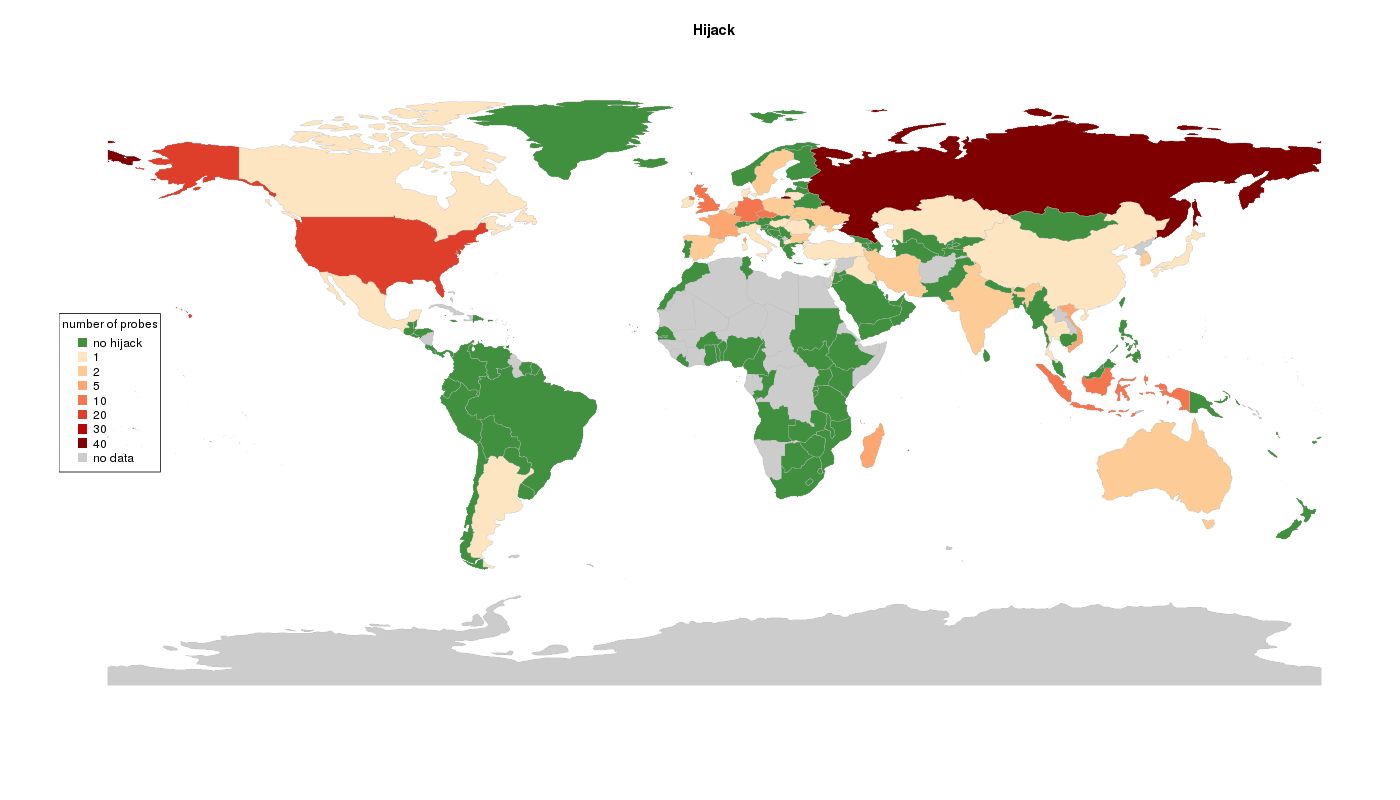
| no | cc | total_probes | hijacked | perc_hijacked |
|---|---|---|---|---|
| 1 | RU | 445 | 34 | 7.6 % |
| 2 | US | 978 | 12 | 1.2 % |
| 3 | DE | 1117 | 8 | 0.7 % |
| 4 | GB | 556 | 8 | 1.4 % |
| 5 | CZ | 241 | 7 | 2.9 % |
| 6 | ID | 40 | 7 | 17.5 % |
| 7 | FR | 729 | 5 | 0.7 % |
| 8 | MG | 6 | 3 | 50.0 % |
| 9 | VN | 5 | 3 | 60.0 % |
| 10 | AU | 118 | 2 | 1.7 % |
| 11 | BE | 183 | 2 | 1.1 % |
| 12 | BG | 71 | 2 | 2.8 % |
| 13 | ES | 134 | 2 | 1.5 % |
| 14 | IN | 31 | 2 | 6.5 % |
| 15 | IR | 48 | 2 | 4.2 % |
| 16 | KR | 14 | 2 | 14.3 % |
| 17 | PL | 149 | 2 | 1.3 % |
| 18 | SE | 160 | 2 | 1.2 % |
| 19 | UA | 179 | 2 | 1.1 % |
| 20 | AR | 26 | 1 | 3.8 % |
whoami_asn vs ok
| 0 | 1 | |
|---|---|---|
| 12008 | 1 | 0 |
| 12886 | 1 | 0 |
| 13238 | 5 | 0 |
| 13319 | 1 | 0 |
| 15169 | 10 | 8616 |
| 15440 | 1 | 0 |
| 15493 | 1 | 0 |
| 17816 | 1 | 0 |
| 17885 | 1 | 0 |
| 17974 | 3 | 0 |
| 18403 | 3 | 0 |
| 196782 | 1 | 0 |
| 197349 | 1 | 0 |
| 198496 | 1 | 0 |
| 200001 | 1 | 0 |
| 20485 | 21 | 0 |
| 20631 | 1 | 0 |
| 21581 | 1 | 0 |
| 2519 | 1 | 0 |
| 2611 | 1 | 0 |
| 2856 | 7 | 0 |
| 29518 | 2 | 0 |
| 29608 | 1 | 0 |
| 30607 | 1 | 0 |
| 3209 | 4 | 0 |
| 3356 | 1 | 0 |
| 35539 | 1 | 0 |
| 35761 | 1 | 0 |
| 36692 | 19 | 0 |
| 37054 | 3 | 0 |
| 38896 | 1 | 0 |
| 39608 | 1 | 0 |
| 42395 | 1 | 0 |
| 42610 | 1 | 0 |
| 44217 | 1 | 0 |
| 44566 | 1 | 0 |
| 45629 | 1 | 0 |
| 4766 | 1 | 0 |
| 4802 | 1 | 0 |
| 48847 | 1 | 0 |
| 49100 | 1 | 0 |
| 52328 | 1 | 0 |
| 5467 | 1 | 0 |
| 57172 | 1 | 0 |
| 59815 | 1 | 0 |
| 6621 | 1 | 0 |
| 680 | 1 | 0 |
| 7922 | 2 | 0 |
| 8334 | 1 | 0 |
| 8468 | 1 | 0 |
| 8687 | 1 | 0 |
| 8708 | 1 | 0 |
| 9121 | 1 | 0 |
| N/A | 7 | 0 |
Weka tree

Interesting cases
Resolvers that were classified as hijacked had significantly longer RTT for a DNS query. While PING RTT was expected to be shorter, we consider longer DNS RTT to be justified. That is because hijacked resolver was isolated and had to perform full name resolution process, while 8.8.8.8 server most likely had already a proper RR in its cache (presumably many of RIPE Atlas probes queried the same instance of Google Public DNS).
> summary(df[which(df$ok==0),]$whoami_rt)
Min. 1st Qu. Median Mean 3rd Qu. Max.
1.892 13.740 40.530 113.300 87.100 3718.000
> summary(df[which(df$ok==1),]$whoami_rt)
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.674 14.860 30.020 43.560 62.050 1737.000
This assumption seems to be confirmed by the results of a query for hostname.bind CHAOS record. DNS RTT for such queries from hijacked servers was much shorter, that it because it didn’t involve name resolution process.
> summary(df[which(df$ok==0),]$chaos1_rt)
Min. 1st Qu. Median Mean 3rd Qu. Max.
1.214 2.591 12.450 43.530 34.730 1455.000
> summary(df[which(df$ok==1),]$chaos1_rt)
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.547 13.440 27.690 41.110 56.310 3176.000
How to use it
At first we need to setup environment:
$ git clone https://github.com/recdnsfp/ripe_atlas_api_scipts
$ pip install geoip pycurl dnsip
# As we store data in arff format, we also need to have parser installed
$ git clone https://github.com/iitis/arff-tools
# Modify your api key (go to atlas.ripe.net to create our api key)
$ vim get_results.py create_measurement_all_probes.py
Another step is to extract features from dns resolvers. We do it by sending different dns queries from each atlas probe. This step needs to be repeated for each dns feature (dnssec, nxdomain etc):
# Download the list of probes
$ wget http://ftp.ripe.net/ripe/atlas/probes/archive/2017/04/20170419.json.bz2
$ bunzip2 20170419.json.bz2
$ mkdir results
$ ./create_measurement_all_probes.py YOUR_TEMPLATE.json 20170419.json results_ids.json
# wait 5-10 min for measurement to finish
$ ./get_results.py results_ids.json results
$ ./merge_results.py results_ids.json results merged.json
This set of command will give you json files with the queries results. For each dns feature we stored results in github repository: https://github.com/recdnsfp/datasets
Once we have all data collected we can move forward and parse the data:
$ git clone https://github.com/recdnsfp/parsejson.git
# Run parser for each feature, for example:
$
./parsejson.py \
--dsfail ../datasets/dnssec_failed.json \
--nxd ../datasets/nxdomain.json \
--dnskey ../datasets/do_dnskey.json \
--nsid ../datasets/nsid.json \
--chaos ../datasets/chaos_bind_version.json ../datasets/hostname_bind.json \
--whoami ../datasets/whoami.json \
--ipv6 ../datasets/ipv6_only_authorative.json \
> ../datasets/RESULTS-ALL-FEATURES.arff
# "Ground truth"
$ grep -f ../datasets/GOOD-PROBES.txt ../datasets/RESULTS-ALL-FEATURES.arff | sed -re 's;$;,1;g' > ../datasets/RESULTS-1600.arff
$ grep -f ../datasets/BAD-PROBES.txt ../datasets/RESULTS-ALL-FEATURES.arff | sed -re 's;$;,0;g' >> ../datasets/RESULTS-1600.arff
# Add headers
$ curl "https://gist.githubusercontent.com/mkaczanowski/e3e3384a1ba525b403ed590e8db1c9b3/raw/e81b5d4ffe2fd4cee73256c59e4f19d7aae8baf5/gistfile1.txt"
At this point we are all set to train algorithm with the data. In this example we use python but you can also use weka (http://www.cs.waikato.ac.nz/ml/weka/)
# Split into testing/training
$ cat RESULTS-1600.arff | ~/arff-tools/arff-sample 50 -f > RESULTS-1600-train.arff 2> RESULTS-1600-test.arff
# Train the model
$ ./ml.py --train ../datasets/RESULTS-1600-train.arff --store ~/tmp/model2
$ ../datasets/RESULTS-1600-train.arff: read 4298 samples
# Test the model
./ml.py --test ../datasets/RESULTS-1600-test.arff --load ~/tmp/model2
../datasets/RESULTS-1600-test.arff: read 4347 samples
probability for id 1123 being 1 is 0.9
probability for id 2290 being 1 is 0.9
probability for id 2525 being 1 is 0.7
probability for id 3600 being 1 is 0.9
probability for id 10248 being 1 is 0.9
probability for id 15330 being 1 is 0.9
probability for id 24900 being 1 is 0.7
probability for id 28541 being 0 is 0.9
test: ok=4347 err=0
Conclusions
We did our analysis only for Google Public DNS, but we highlight that our method is not limited to Google, and can easily be applied to other operators as well.
Our fingerprinting approach can also be used to detect a somehow opposite problem: an ISP pretending to be operating their own caching recursive DNS servers, but in reality redirecting their traffic to Google or OpenDNS resolvers.
Credits
Made on RIPE DNS measurements hackathon (20-04-2017 - 21-04-2017) by:
- Pawel Foremski
- Maciej Andziński
- Mateusz Kaczanowski
- Marta van der Haagen (graphics)